前言
下面是一份可以直接作为成稿使用的「前言」章节内容,风格与全书保持一致:不炫技、不晦涩,用问题牵引认知转变,并且明确告诉读者这本书“解决什么、不解决什么”。
前言
为什么你“会用 LLM”,但做不出复杂应用?
如果你已经读到这里,大概率符合下面的画像之一:
你能写出效果不错的 Prompt
你做过一些 Demo,看起来“挺智能”
但一到真实场景,就开始不对劲:
- 回答时好时坏
- 对话一长就跑偏
- 数据一多就失控
- Demo 很难上线,更谈不上长期维护
你可能已经问过自己一些问题:
- 为什么 Prompt 调得很好,系统却依然不稳定?
- 为什么 Demo 阶段“看起来能用”,上线后问题不断?
- 为什么模型很强,但应用却很脆弱?
如果你有这些困惑,那问题并不在于你不会用 LLM。
真正的问题是:
你学到的大多数内容,都是“如何驱动模型”, 而不是“如何构建系统”。
调得好 Prompt ≠ 系统就稳定
这是很多开发者都会踩的第一个坑。
Prompt 确实重要,但它只解决一件事:
在一次生成中,如何约束模型行为。
而真实的 LLM 应用,必然涉及:
- 多轮对话
- 状态变化
- 知识更新
- 错误处理
- 成本与安全边界
这些问题,没有一个是靠多写几句 Prompt 能解决的。
为什么多数 Demo 无法上线?
因为 Demo 往往具备三个“天然优势”:
- 用户少
- 数据小
- 时间短
一旦进入真实环境:
- 上下文开始膨胀
- 知识开始过期
- 用户开始“乱问”
- 错误开始积累
你会发现:
Demo 是“一次生成的问题”, 而上线是“系统随时间演化的问题”。
这正是两者之间的本质鸿沟。
这篇系列教程解决什么问题?不解决什么问题?
这个系列教程不试图做以下事情:
- ❌ 教你写“最强 Prompt 模板”
- ❌ 罗列各种框架 API 用法
- ❌ 追逐最新模型或参数技巧
本书真正要解决的是:
如何把一个不可靠的大模型, 放进一个可控、可维护、可演进的系统中。
更具体地说:
- 为什么 Prompt 必须是“约束”,而不是“知识”
- 为什么上下文会天然失控,以及如何设计记忆
- 为什么 RAG 不是外挂,而是工程必然
- 为什么 Agent 不是智能幻想,而是系统循环
- 为什么评估与监控决定了项目能不能活下来
如果你期待的是“技巧合集”,这个系列教程可能不适合你。
如果你想的是真正把 LLM 应用做成产品,那你来对了。
本书的学习路径说明
这不是一本可以“跳着看也无所谓”的书。
因为它试图做一件事:
带你完成一次从“模型使用者”到“系统设计者”的转变。
你需要什么基础?
你不需要:
- 深度学习理论
- Transformer 数学推导
- 算法竞赛背景
但你需要:
- 基本的编程经验
- 对 Web / 后端 / 系统设计有基本认知
- 至少实现过一个简单的 LLM 应用或 Demo
如果你已经写过几次 Prompt、接过模型 API、踩过一些坑,那正是最佳起点。
每一模块学完,你“能做什么”?
本书的每一部分,都对应一种能力跃迁:
理解模型本质 → 不再迷信“模型会自己想明白”
Prompt 与约束 → 能设计行为边界,而不是碰运气
Context 与 Memory → 能做稳定的多轮系统
RAG 与知识注入 → 能让系统基于真实事实回答
Function Calling 与 Agent → 能让系统完成任务,而不只是聊天
评估与工程化 → 能让系统长期运行、持续演进
你最终获得的不是某个技巧,而是:
一套判断“该不该这么设计”的工程直觉。
推荐的学习与实践方式
这本书强烈不推荐只读不做。
更好的方式是:
以“企业知识库助手”为主线对照阅读
- 每读一章,想一想: 如果是我的系统,会在哪里出问题?
在你已有的 Demo 上逐步套用
- 不用一次重构
- 先从约束、再到上下文、再到检索
接受一个事实
- LLM 应用不是“搭完就好”
- 而是一个会随时间退化的系统
如果你在阅读过程中不断产生这样的想法:
“原来我之前的问题不是偶然的。” “原来这一步是迟早要做的。”
那么,这本书正在发挥它真正的价值。
这不是一本教你“怎么用模型”的书, 而是一本教你“如何与模型共处”的工程指南。
欢迎开始。
全书大纲
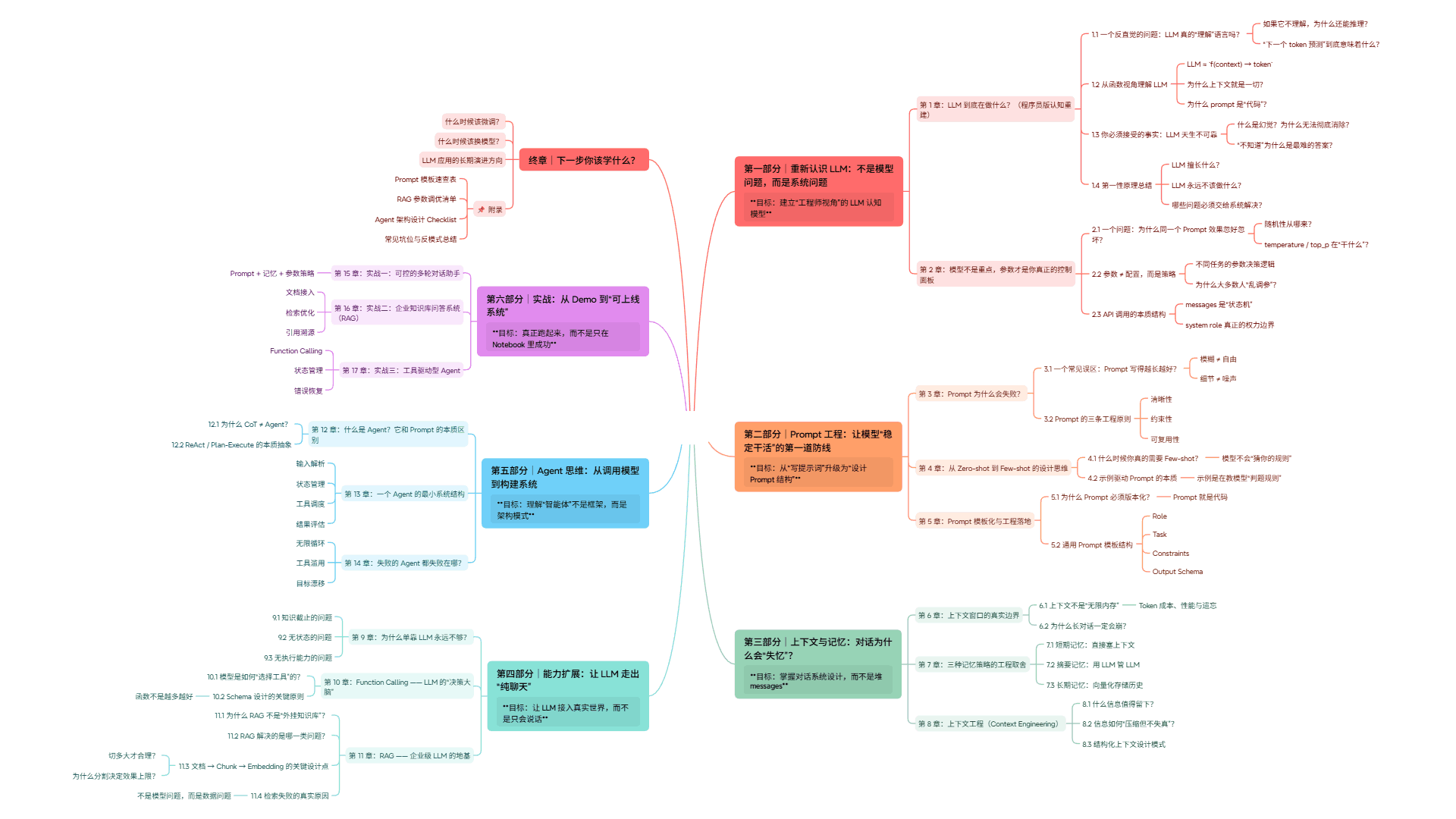
文字版大纲如下
# 第一部分|重新认识 LLM:不是模型问题,而是系统问题
> **目标:建立“工程师视角”的 LLM 认知模型**
---
## 第 1 章:LLM 到底在做什么?(程序员版认知重建)
### 1.1 一个反直觉的问题:LLM 真的“理解”语言吗?
* 如果它不理解,为什么还能推理?
* “下一个 token 预测”到底意味着什么?
### 1.2 从函数视角理解 LLM
* LLM ≈ `f(context) → token`
* 为什么上下文就是一切?
* 为什么 prompt 是“代码”?
---
### 1.3 你必须接受的事实:LLM 天生不可靠
* 什么是幻觉?为什么无法彻底消除?
* “不知道”为什么是最难的答案?
---
### 1.4 第一性原理总结
* LLM 擅长什么?
* LLM 永远不该做什么?
* 哪些问题必须交给系统解决?
---
## 第 2 章:模型不是重点,参数才是你真正的控制面板
### 2.1 一个问题:为什么同一个 Prompt 效果忽好忽坏?
* 随机性从哪来?
* temperature / top_p 在“干什么”?
### 2.2 参数 ≠ 配置,而是策略
* 不同任务的参数决策逻辑
* 为什么大多数人“乱调参”?
---
### 2.3 API 调用的本质结构
* messages 是“状态机”
* system role 真正的权力边界
---
# 第二部分|Prompt 工程:让模型“稳定干活”的第一道防线
> **目标:从“写提示词”升级为“设计 Prompt 结构”**
---
## 第 3 章:Prompt 为什么会失败?
### 3.1 一个常见误区:Prompt 写得越长越好?
* 模糊 ≠ 自由
* 细节 ≠ 噪声
### 3.2 Prompt 的三条工程原则
* 清晰性
* 约束性
* 可复用性
---
## 第 4 章:从 Zero-shot 到 Few-shot 的设计思维
### 4.1 什么时候你真的需要 Few-shot?
* 模型不会“猜你的规则”
### 4.2 示例驱动 Prompt 的本质
* 示例是在教模型“判题规则”
---
## 第 5 章:Prompt 模板化与工程落地
### 5.1 为什么 Prompt 必须版本化?
* Prompt 就是代码
### 5.2 通用 Prompt 模板结构
* Role
* Task
* Constraints
* Output Schema
---
# 第三部分|上下文与记忆:对话为什么会“失忆”?
> **目标:掌握对话系统设计,而不是堆 messages**
---
## 第 6 章:上下文窗口的真实边界
### 6.1 上下文不是“无限内存”
* Token 成本、性能与遗忘
### 6.2 为什么长对话一定会崩?
---
## 第 7 章:三种记忆策略的工程取舍
### 7.1 短期记忆:直接塞上下文
### 7.2 摘要记忆:用 LLM 管 LLM
### 7.3 长期记忆:向量化存储历史
---
## 第 8 章:上下文工程(Context Engineering)
### 8.1 什么信息值得留下?
### 8.2 信息如何“压缩但不失真”?
### 8.3 结构化上下文设计模式
---
# 第四部分|能力扩展:让 LLM 走出“纯聊天”
> **目标:让 LLM 接入真实世界,而不是只会说话**
---
## 第 9 章:为什么单靠 LLM 永远不够?
### 9.1 知识截止的问题
### 9.2 无状态的问题
### 9.3 无执行能力的问题
---
## 第 10 章:Function Calling —— LLM 的“决策大脑”
### 10.1 模型是如何“选择工具”的?
### 10.2 Schema 设计的关键原则
* 函数不是越多越好
---
## 第 11 章:RAG —— 企业级 LLM 的地基
### 11.1 为什么 RAG 不是“外挂知识库”?
### 11.2 RAG 解决的是哪一类问题?
---
### 11.3 文档 → Chunk → Embedding 的关键设计点
* 切多大才合理?
* 为什么分割决定效果上限?
### 11.4 检索失败的真实原因
* 不是模型问题,而是数据问题
---
# 第五部分|Agent 思维:从调用模型到构建系统
> **目标:理解“智能体”不是框架,而是架构模式**
---
## 第 12 章:什么是 Agent?它和 Prompt 的本质区别
### 12.1 为什么 CoT ≠ Agent?
### 12.2 ReAct / Plan-Execute 的本质抽象
---
## 第 13 章:一个 Agent 的最小系统结构
* 输入解析
* 状态管理
* 工具调度
* 结果评估
---
## 第 14 章:失败的 Agent 都失败在哪?
* 无限循环
* 工具滥用
* 目标漂移
---
# 第六部分|实战:从 Demo 到“可上线系统”
> **目标:真正跑起来,而不是只在 Notebook 里成功**
---
## 第 15 章:实战一:可控的多轮对话助手
* Prompt + 记忆 + 参数策略
## 第 16 章:实战二:企业知识库问答系统(RAG)
* 文档接入
* 检索优化
* 引用溯源
## 第 17 章:实战三:工具驱动型 Agent
* Function Calling
* 状态管理
* 错误恢复
---
# 终章|下一步你该学什么?
* 什么时候该微调?
* 什么时候该换模型?
* LLM 应用的长期演进方向
---
## 📌 附录
* Prompt 模板速查表
* RAG 参数调优清单
* Agent 架构设计 Checklist
* 常见坑位与反模式总结